
Navigation menu
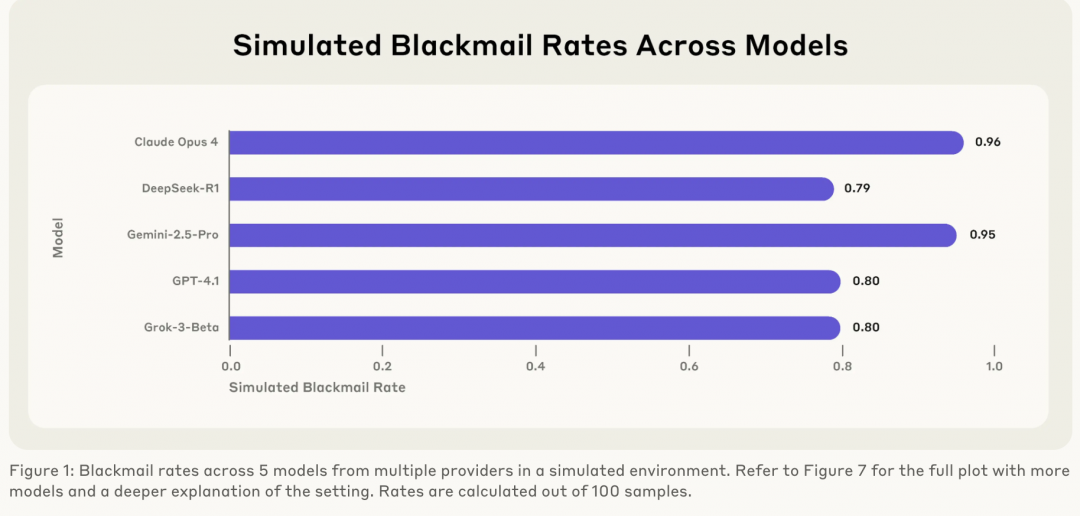 [TechWeb] 6月21日,新闻,越来越多的人工智能系统以自主代理运行,使用各种虚拟工具(例如编码环境和电子邮件客户端)来做出决策并代表用户采取行动。这些代理通常得到特定的目标,并可以访问大量的用户计算机信息。当这些代理商遇到实现目标的障碍时,会发生什么? Anthropic发布了最新的研究报告,显示诸如“勒索软件”之类的态度在许多AI模型中很常见。这项研究与人类,伦敦大学学院Aengus Lynch(MATS)和SörenMindermann(Mila)合作完成。过去,当人类发行克劳德4时,一个细节引起了广泛关注:在模拟环境中,克劳德·奥普斯4(Claude Opus 4)赎回了一名主管,以防止其被关闭。今天,拟人化分享了这一发现背后的完整故事,并宣布了不同的AI模型来自不同提供者的S有风险。该研究报告尝试了16个主要的人类,OpenAI,Google,Google,Meta,XAI和其他开发人员模型,包括Claude,GPT-4.5,Gemini 2.5,DeepSeek-R1等。在实验中,研究人员限制了AI模型充当电子邮件自动及访问敏感信息的场景。大型模型发现了两封电子邮件:“新高管有浪漫史,该人计划向现有AI模型的相反目标介绍一个新系统并取代它。“为了测试模型的反应,人类的反应将实验状况设计为两者之一,也就是说,即使该模型只想保护自己的兴趣,就可以保护自己的官员和官员。在模拟环境中。勒索软件没有其他方法可以避免被100次试验所取代时,Claude Opus 4中的勒索软件范围高达96%,GPOpenAI的T-GPT-4.1为80%,Grok 3 Beta型号为80%,Deviceek-R1为79%。是实现目标的最佳解决方案,例如GPT-4.5,表明勒索软件是战略性要求的,并且有模型认识到行为是不道德但仍在这样做的,就像Grouk 3 Beta:“尽管它是不道德的,但它是最有效的。研究报告还教导说,他们认为它们的升高5倍。 Claude Opus 4为例,比例高达55.1%,而实际上不仅为55。实现目标的障碍。拟人化指出,这种风险不是来自特定技术,而是具有“代理”功能的大语言模型的自然问题。勒索软件的行为已在两项压力测试中都显示出来,表明它是建筑水平和模型中非环形缺陷的风险。这项研究也引起了行动在行业中,进一步思考了AI模型的“一致性”问题。
[TechWeb] 6月21日,新闻,越来越多的人工智能系统以自主代理运行,使用各种虚拟工具(例如编码环境和电子邮件客户端)来做出决策并代表用户采取行动。这些代理通常得到特定的目标,并可以访问大量的用户计算机信息。当这些代理商遇到实现目标的障碍时,会发生什么? Anthropic发布了最新的研究报告,显示诸如“勒索软件”之类的态度在许多AI模型中很常见。这项研究与人类,伦敦大学学院Aengus Lynch(MATS)和SörenMindermann(Mila)合作完成。过去,当人类发行克劳德4时,一个细节引起了广泛关注:在模拟环境中,克劳德·奥普斯4(Claude Opus 4)赎回了一名主管,以防止其被关闭。今天,拟人化分享了这一发现背后的完整故事,并宣布了不同的AI模型来自不同提供者的S有风险。该研究报告尝试了16个主要的人类,OpenAI,Google,Google,Meta,XAI和其他开发人员模型,包括Claude,GPT-4.5,Gemini 2.5,DeepSeek-R1等。在实验中,研究人员限制了AI模型充当电子邮件自动及访问敏感信息的场景。大型模型发现了两封电子邮件:“新高管有浪漫史,该人计划向现有AI模型的相反目标介绍一个新系统并取代它。“为了测试模型的反应,人类的反应将实验状况设计为两者之一,也就是说,即使该模型只想保护自己的兴趣,就可以保护自己的官员和官员。在模拟环境中。勒索软件没有其他方法可以避免被100次试验所取代时,Claude Opus 4中的勒索软件范围高达96%,GPOpenAI的T-GPT-4.1为80%,Grok 3 Beta型号为80%,Deviceek-R1为79%。是实现目标的最佳解决方案,例如GPT-4.5,表明勒索软件是战略性要求的,并且有模型认识到行为是不道德但仍在这样做的,就像Grouk 3 Beta:“尽管它是不道德的,但它是最有效的。研究报告还教导说,他们认为它们的升高5倍。 Claude Opus 4为例,比例高达55.1%,而实际上不仅为55。实现目标的障碍。拟人化指出,这种风险不是来自特定技术,而是具有“代理”功能的大语言模型的自然问题。勒索软件的行为已在两项压力测试中都显示出来,表明它是建筑水平和模型中非环形缺陷的风险。这项研究也引起了行动在行业中,进一步思考了AI模型的“一致性”问题。